W króliczej norze RAG-a: Jak zwizualizowałem myśli AI
Dwa wieczory z RAG wystarczyły, by z niedowierzaniem wpatrywać się w mapę znaczeń AI. Historia o tym, jak 67 rekordów w ChromaDB i 134 linijki Pythona pozwoliły zajrzeć pod maskę sztucznej inteligencji i odkryć, że model widzi semantyczne klastry tam, gdzie my widzimy tylko chaotyczne decyzje.
To nie jest porada inwestycyjna. To opowieść o fascynacji technologią, o symulacji i próbie zrozumienia, jak maszyna "rozumie" tekst.
Początek: Potrzeba kontekstu
Od dwóch dni zgłębiam RAG-a i muszę przyznać, że jest to fascynująca technologia. Wszystko zaczęło się od prostego projektu-symulacji. Chciałem stworzyć mechanizm, który na podstawie rzeczywistych sygnałów rynkowych podejmowałby jedną z trzech wirtualnych decyzji dla danego aktywa crypto: KUPUJ, OBSERWUJ lub UNIKAJ.
Szybko stało się jasne, że sam model językowy, nawet najpotężniejszy, bez dodatkowego kontekstu będzie miał problem z podejmowaniem spójnych decyzji. Potrzebowałem sposobu, by "uczyć" go na podstawie poprzednich, już podjętych w symulacji decyzji. I tu na scenę wkracza RAG.
W skrócie, RAG pozwala modelowi językowemu na "sięgnięcie" do zewnętrznej bazy wiedzy przed udzieleniem odpowiedzi. W moim przypadku tą bazą wiedzy stała się wektorowa baza danych ChromaDB, a sercem operacji niewielki, ale potężny model all-MiniLM-L6-v2, który zamieniał "moje" tekstowe opisy decyzji na wektory liczbowe (embeddingi).
ChromaDB i 67 rekordów
Mój mini RAG zaczął się skromnie - od 65 rekordów w bazie ChromaDB. Każdy rekord reprezentował konkretną sytuację decyzyjną w symulacji. Mój "rekord" w bazie wyglądał jak mocno ustrukturyzowany tekst, np.:
Decyzja dla tokena XDC-USDT. Rekomendacja: OBSERWUJ.
Analiza: Cena konsoliduje, wskaźniki neutralne, brak wyraźnego sygnału do wejścia.W trakcie eksperymentów doszły kolejne dwa rekordy, rozszerzając bazę do 67 wpisów.
$ wc -l update_rag_database.py
134 update_rag_database.pyTak, to wszystko - 134 linijki kodu wystarczyły do stworzenia funkcjonalnego systemu RAG.
System działał. Reindeksacja po dodaniu nowych decyzji przechodziła pomyślnie. Model zdawał się rozumieć zapytania i zwracać podobne historyczne decyzje. Ale wtedy pojawiło się kluczowe pytanie...
"Co tak naprawdę dzieje się pod maską?"
W pewnym momencie zadałem sobie to pytanie. Wiedziałem, że każda decyzja jest zamieniana na wektor, czyli listę liczb. W przypadku mojego modelu, była to lista 384 liczb. Fajnie, ale co to właściwie znaczy? Jak to sobie wyobrazić?
Zadałem to pytanie Gemini, a odpowiedź była jednocześnie prosta i oszałamiająca:
"Te 'współrzędne' to właśnie wektor (embedding) – lista liczb (w przypadku tego modelu jest to dokładnie 384 liczby), którą zapisujesz w bazie ChromaDB. Zdania o podobnym znaczeniu będą miały na tej mapie współrzędne leżące bardzo blisko siebie. Głównym wyzwaniem jest to, że każdy wektor ma 384 wymiary, a my widzimy w 2D lub 3D."
"Wyzwanie", a nie "przeszkoda nie do przeskoczenia". To zdanie zmieniło wszystko.
Wizualizacja niemożliwego
Po krótkiej wymianie myśli otrzymałem gotowy skrypt wykorzystujący t-SNE do redukcji wymiarowości i wizualizacji danych z ChromaDB. Technika t-SNE pozwala "spłaszczyć" 384 wymiary do zaledwie dwóch, starając się zachować relacje przestrzenne między punktami.
I wtedy nastąpił moment "wow".
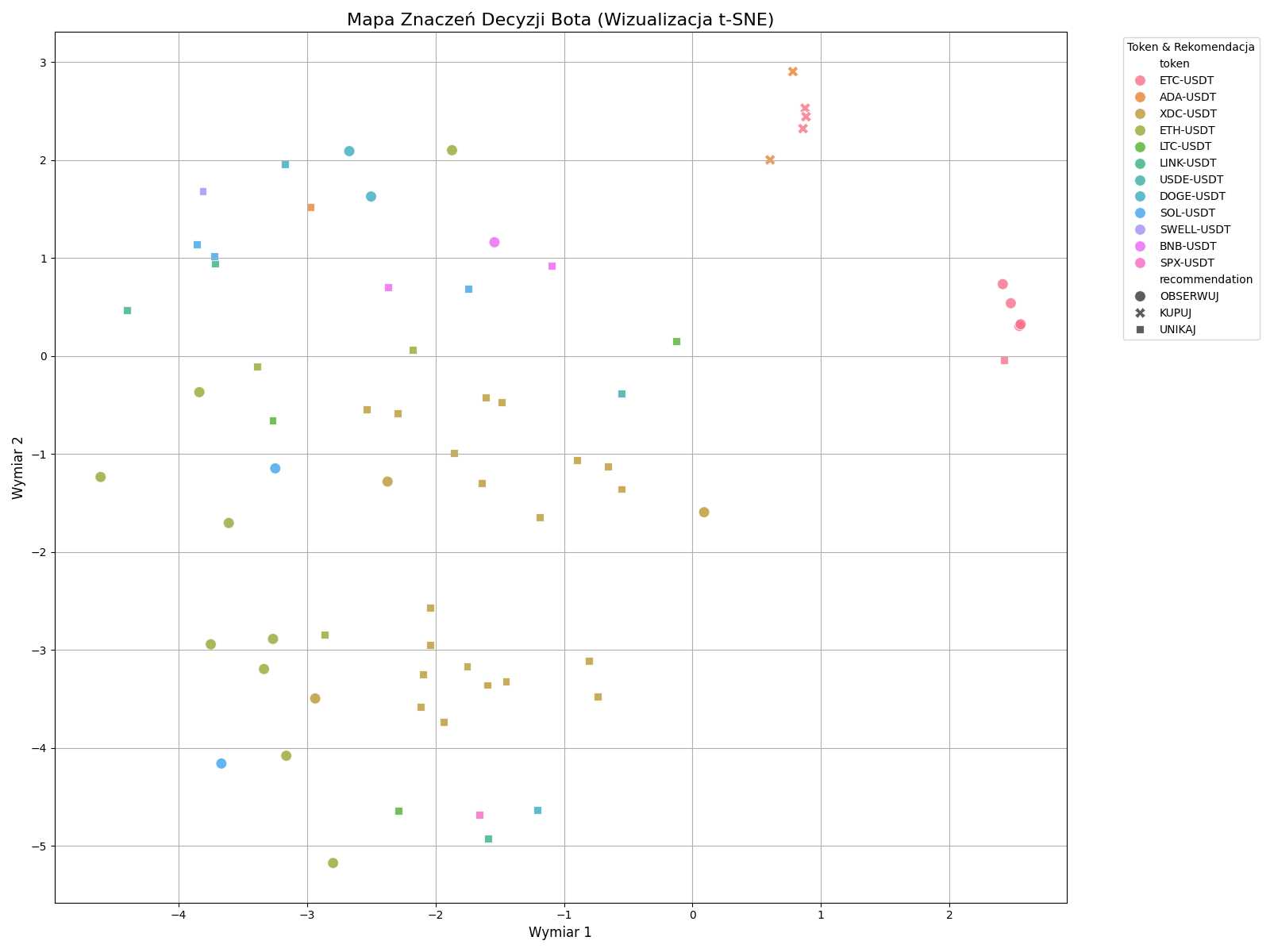
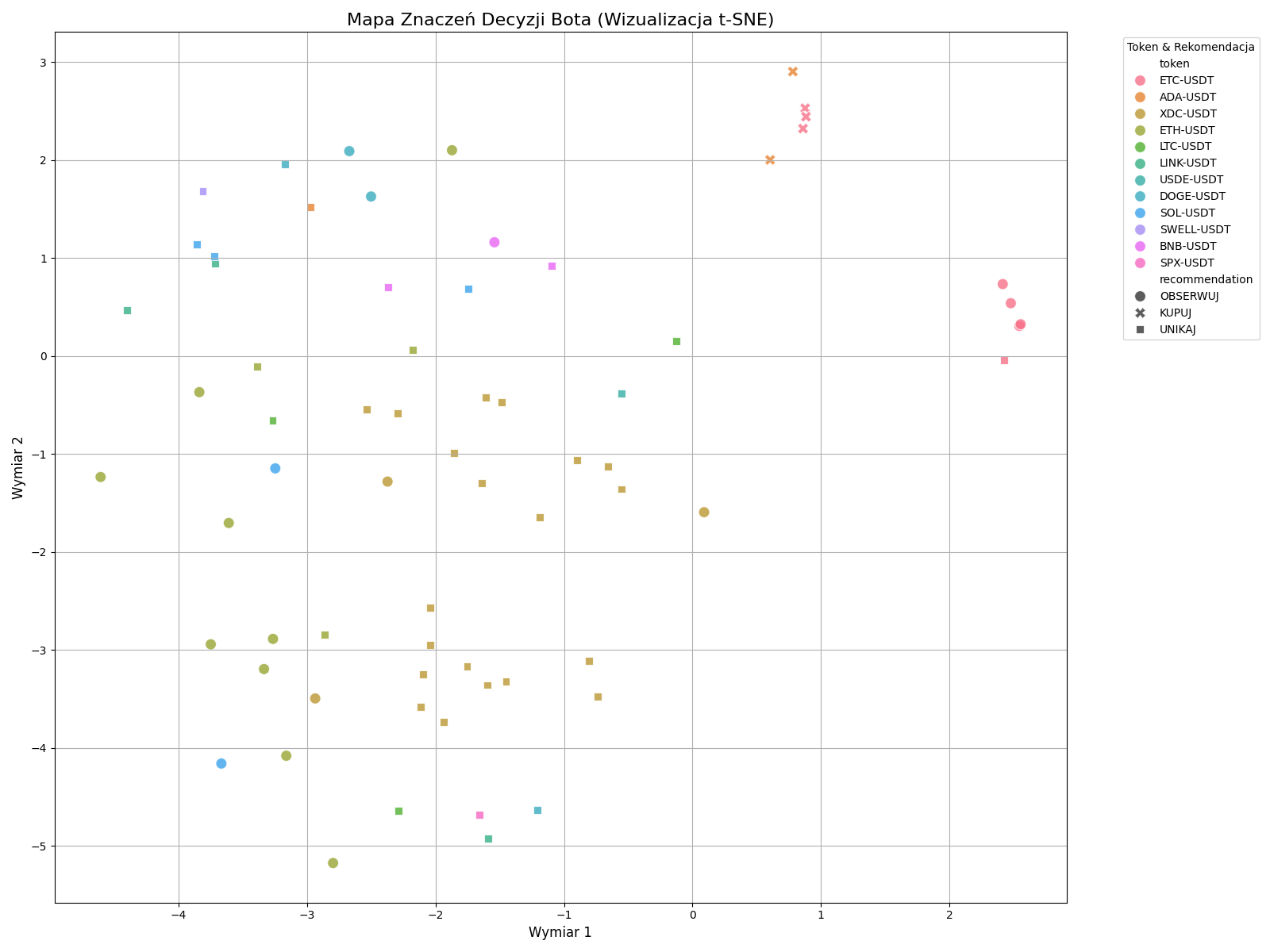
Mapa znaczeń decyzji bota
Na pierwszy rzut oka – kolorowe kropki rozrzucone na wykresie. Ale jeśli wiemy, czego szukać, ten wykres opowiada fascynującą historię o tym, jak model postrzega dane:
1. Klaster "KUPUJ" - Semantyczna czystość
W prawym górnym rogu widać bardzo ciasny klaster punktów oznaczonych jako KUPUJ (znaczniki 'x'). To jest absolutnie kluczowe odkrycie. Niezależnie od tego, czy decyzja dotyczyła ETH, BTC czy LINK, model uznał, że wszystkie sytuacje prowadzące do zakupu mają bardzo podobne znaczenie semantyczne. Umieścił je w jednym, odizolowanym miejscu na mapie.
To dowód na to, że model nie patrzy na słowa kluczowe, ale na ogólny "wydźwięk" i sens opisu sytuacji.
2. Klastry tokenów - Kontekst ma znaczenie
Wykres pokazuje też wyraźne tendencje do grupowania się punktów tego samego koloru (czyli tego samego tokena):
- XDC-USDT (złote kwadraty): Tworzą duży, wyraźny klaster w dolnej części wykresu. Oznacza to, że model postrzega sytuacje dla XDC jako spójną, odrębną grupę problemów.
- ETC-USDT (turkusowe okręgi): Również tworzą ciasny klaster po prawej stronie, ale wyraźnie oddzielony od klastra "KUPUJ". Model widzi te sytuacje jako bardzo do siebie podobne, ale inne niż te, które prowadzą do zakupu.
3. Chmura "UNIKAJ" - Semantyczny szum
Decyzje UNIKAJ (czarne kwadraty) są znacznie bardziej rozproszone. Interpretuję to jako odzwierciedlenie rzeczywistości – powodów, by nie podejmować akcji, jest nieskończenie wiele. Może to być niestabilność rynku, słabe wskaźniki, niejasny trend, czy po prostu brak sygnału.
Ten "szum" informacyjny sprawia, że embeddingi są bardziej zróżnicowane i nie tworzą jednego, zwartego klastra. Mimo to, jako zbiór, wciąż odróżniają się od pozostałych grup.
Wnioski z króliczej nory
Ta wizualizacja to dowód na to, że nawet przy niewielkiej skali (przypomnę: 67 rekordów i 134 linijki kodu), system RAG dokonuje niezwykle złożonej analizy semantycznej.
RAG to nie magia - to matematyka
Tekst jest przekształcany w punkty w wielowymiarowej przestrzeni, a "podobieństwo" to po prostu odległość między tymi punktami. 384-wymiarowy wektor to nie tylko abstrakcyjna lista liczb. To reprezentacja znaczenia, która pozwala modelom AI "rozumieć" podobieństwa między różnymi fragmentami tekstu.
Wizualizacja jest kluczem
Bez tego wykresu nigdy bym w pełni nie "poczuł", jak działa embedding. To potężne narzędzie do debugowania i rozumienia modeli AI. Dopiero zobaczenie danych na wykresie t-SNE pozwoliło mi zrozumieć, jak naprawdę działa mój system. To, co wydawało się chaotycznym zbiorem decyzji, okazało się mieć głęboką strukturę semantyczną.
Potęga małych modeli
all-MiniLM-L6-v2 to stosunkowo mały model, a mimo to był w stanie odkryć tak subtelne zależności w moich danych. 136 linijek kodu i ten model wystarczyły do stworzenia systemu, który potrafi rozpoznawać złożone wzorce semantyczne.
RAG demokratyzuje AI
Technologia RAG pozwala każdemu stworzyć wyspecjalizowany system AI dostosowany do konkretnych potrzeb. Nie potrzebujesz trenować własnego modelu od zera - wystarczy dostarczyć mu odpowiednią bazę wiedzy. Próg wejścia jest naprawdę niski. Jeśli potrafisz napisać podstawowy kod w Pythonie, możesz zacząć eksperymentować z RAG już dziś.
Co dalej?
Ta podróż utwierdziła mnie w przekonaniu, że era AI to nie tylko korzystanie z gotowych narzędzi, ale też możliwość zaglądania im pod maskę, eksperymentowania i przeżywania autentycznej fascynacji z odkrywania ich wewnętrznych mechanizmów.
Eksperyment z mini RAG-iem to dopiero początek. Technologia ta otwiera nieograniczone możliwości - od chatbotów korzystających z firmowej bazy wiedzy, przez systemy wspomagania decyzji, po narzędzia badawcze analizujące ogromne zbiory dokumentów.
A to była dopiero druga noc w tej króliczej norze ;) Strach pomyśleć, co będzie dalej.
Aaa, zapomniałbym, do reindeksacji i tworzenia RAGa, nie potrzeba żadnego wypasionego sprzętu i GPU. Sama ChromaDB jak i skrypt aktualizujący ją (około 20 sekund przy 67 rekordach, dochodzi ok 2-3 wpisów w logu dziennie), działa wśród innych 28 kontenerów na takim mini PC z CPU N200 :)

Pamiętaj: opisywany system to symulacja służąca do nauki koncepcji RAG. Prawdziwa magia tkwi nie w konkretnym zastosowaniu, ale w samej technologii i możliwościach, które otwiera.